ToC
Athena Federated Queryとは…
突然ですが、S3以外のデータソースに対してAthenaからSQLを実行したい場合がありますよね。
前回紹介したAWSサービスの「セキュリティログ」だけでなく、LambdaやFargateといったサービスのログは
Clowdwatch Logsに直接出力されていたりします。
もちろん、Kinesis firehoseを経由してS3に保存してからAthenaで検索するという方法もあると思いますが、
Athena Federated Queryのコネクタを利用すると直接、Athenaからクエリが実行できるようになります。
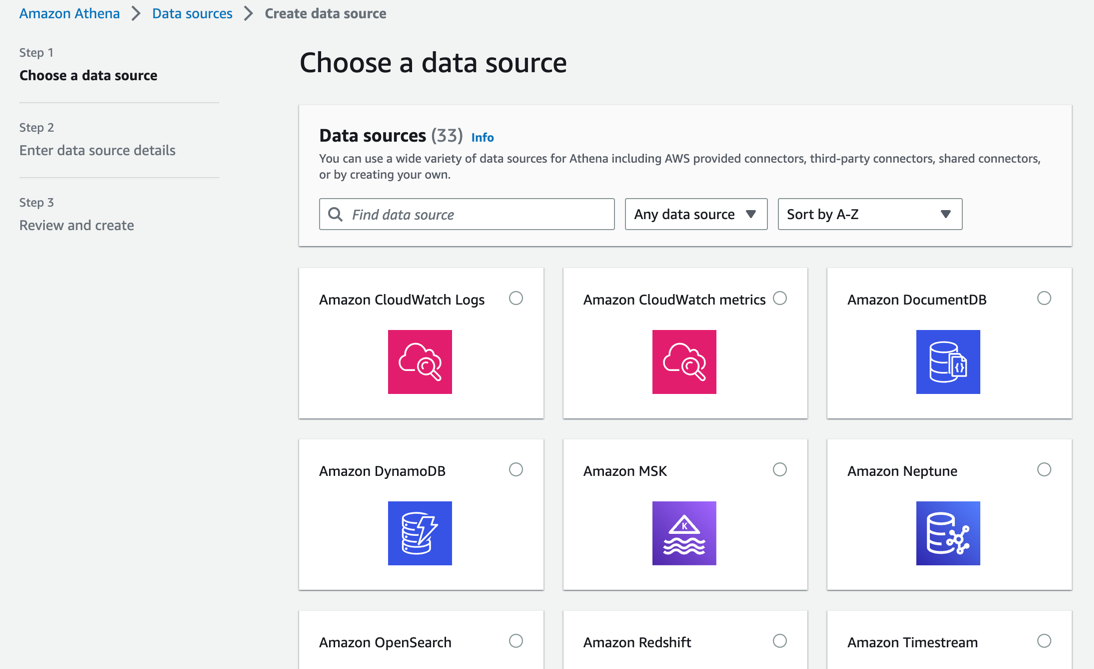
Athenaのデータソースとして登録する画面を見てみると対象はAWSサービスをはじめ、各種のサードパーティソフトウエアや カスタムで作成することもできるようです。今回は、Amazon Athena CloudWatch connectorのドキュメントに 沿って、Cloudwatch Logsのログを検索できるようにしてみようと思います。
Amazon Athena Query Federation
AWS Labsにて、Amazon Athena Query FederationというSDKが公開されており、こちらを活用することで
簡単に始めることができるようです。Athena V2エンジンが必須と記載がありましたが、手元の環境はV3のエンジンでしたので
検証も兼ねて進めていみたいと思います。
システム構成
ざっとした構成を確認してみましょう。
マネジメントコンソールのAthena Query editorから、データソースとして指定されたConnectorのLambdaを実行して
情報取得するようです。途中でデータソースから取得したデータを一時的に書き出すため、S3のSpillBucketにオブジェクト出力することもあるようです。
また、接続先のサービスごとのConnector Lambdaは、別途デプロイする必要があるようです。
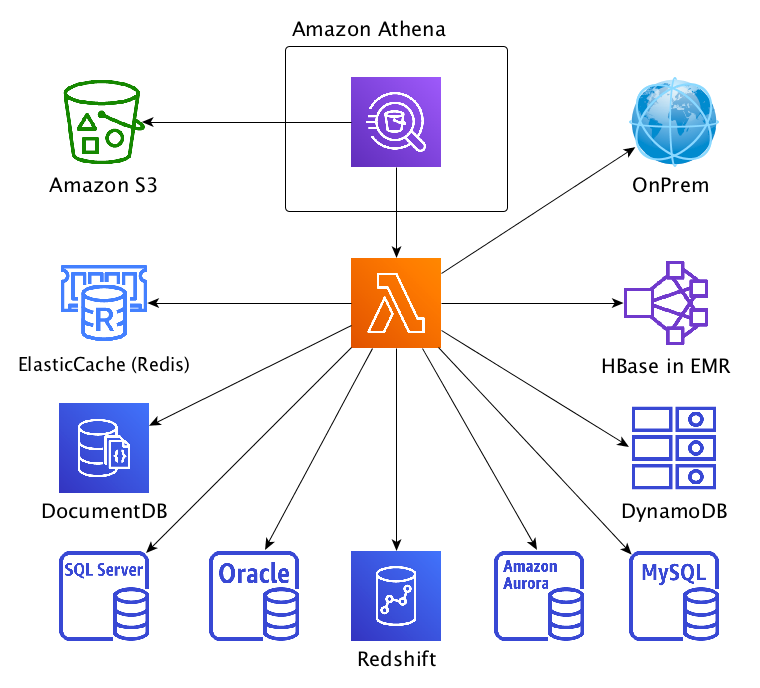
コネクタアプリのデプロイ
今回は、Cloudwatch Logsのログ検索が目的ですので、Amazon Athena Query Federationの
athena-cloudwatchというコネクタをデプロイしてみたいと思います。
Gitを見るとCloudFormationのデプロイテンプレートとソースコードがあります。
コネクタごとのjarファイルもリリースごとに提供されています。
Javaのビルド環境を作るのは、、という場合には、jarファイルを使うのが良いと思います。
ConnectorのLambdaに必要な権限を見るとCloudwatch LogsとS3ということでした。 実際の運用時には、Git上のテンプレートを参考にしてアクセス許可対象とするリソースを少し絞って利用することが良いかもしれません。
PolicyDocument:
Version: 2012-10-17
Statement:
- Action:
- logs:Describe*
- logs:Get*
- logs:List*
- logs:StartQuery
- logs:StopQuery
- logs:TestMetricFilter
- logs:FilterLogEvents
- athena:GetQueryExecution
- s3:ListAllMyBuckets
Effect: Allow
Resource: '*'
- Action:
- s3:GetObject
- s3:ListBucket
- s3:GetBucketLocation
- s3:GetObjectVersion
- s3:PutObject
- s3:PutObjectAcl
- s3:GetLifecycleConfiguration
- s3:PutLifecycleConfiguration
- s3:DeleteObject
Effect: Allow
Resource:
- [SpillBucket出力先]
デプロイテンプレートは、AWS::Serverless::Functionで書かれていましたが、
AWS::Lambda::Functionの方が好みなので、書き換えて利用しました。
また、jarファイルはv2023.18.1のものを利用しました。今回は検証のため
spill_bucket上でのファイルの暗号化は特に行っておりませんが、必要に応じて実施してください。
LambdaFunction:
Type: "AWS::Lambda::Function"
Properties:
FunctionName: [Lambda function名]
Handler: com.amazonaws.athena.connectors.cloudwatch.CloudwatchCompositeHandler
Runtime: java11
Code:
S3Bucket: [jar格納バケット名]
S3Key: [jarパス]
MemorySize: 512
Timeout: 30
Role: [Lambda実行Role]
DeadLetterConfig:
TargetArn: [Dead Letter Queue Arn]
Architectures:
- "arm64"
PackageType: "Zip"
Environment:
Variables:
disable_spill_encryption: true
spill_bucket: !Ref SpillBucket
spill_prefix: !Ref SpillPrefix
kms_key_id: !Ref "AWS::NoValue"
なお、余談ですが、コスト削減のため、はじめはMemorySizeを128 MBにしたミニマムスペックで実行を試みたのですが、
Exception: java.lang.OutOfMemoryErrorが頻発して、前に進まなかったのでメモリーサイズを変更しました。
Data sources設定
Connector Lambdaのデプロイが完了したら、Data sourcesの設定をします。
Data source名を指定して、Connection detailsのところで先ほどデプロイしたLambdaを指定します。
Lambdaの指定は、Alias指定も可能ですので、必要に応じて設定を行います。
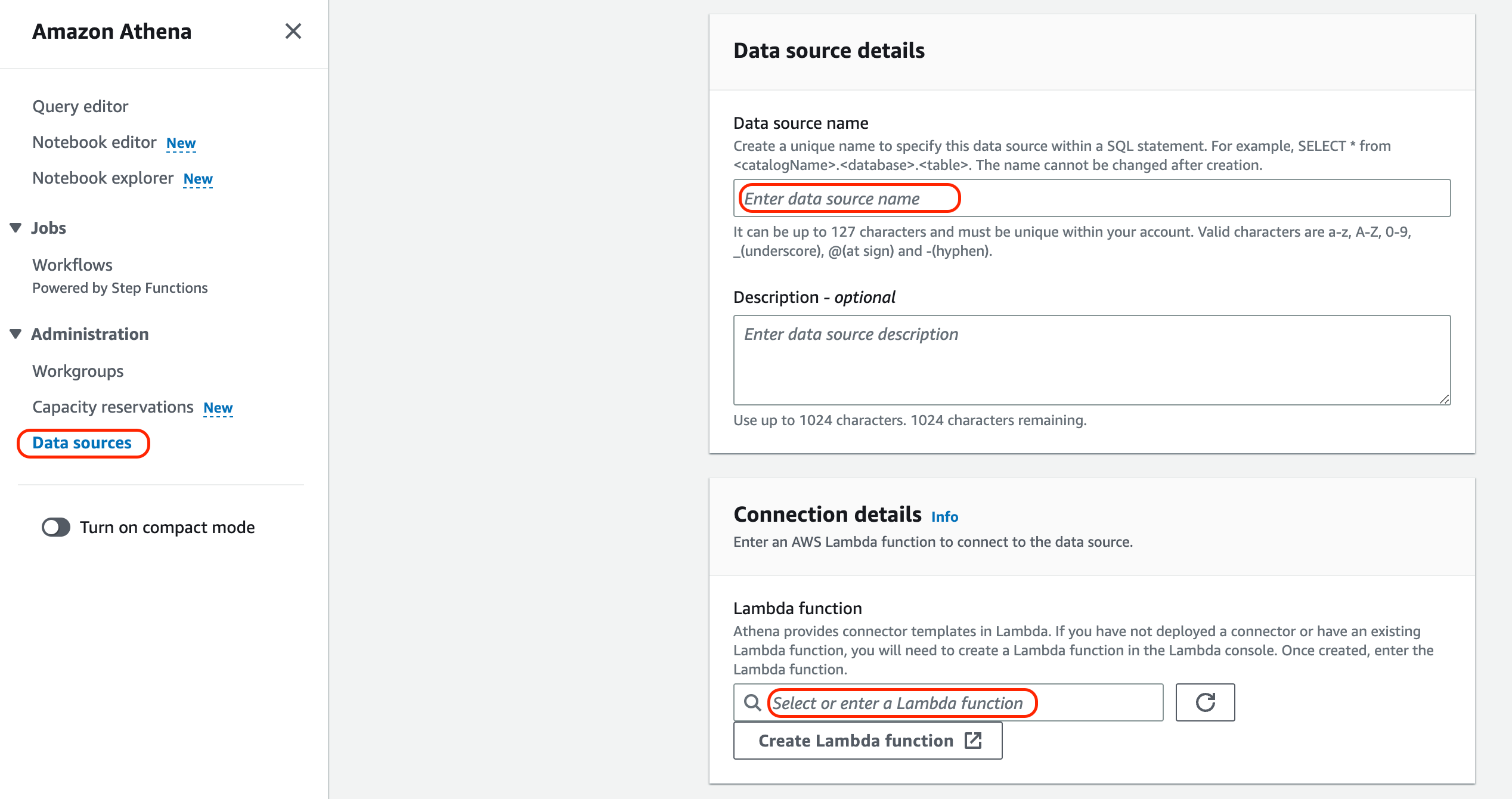
AthenaからCloudwatch Logsの検索
ここまでの設定が完了すれば、Athena Query editorからSQLを実行することができます。
Data sourceのところで、先ほど作成したデータソースを選択するとDatabaseとして、CloudWatch Logsの
ロググループが表示されるようになります。
また、各ロググループ内のログストリームはTableとして定義されます。全てのログストリームを横断して検索するために
all_log_streamsというテーブルが準備されているところは、非常に便利ですね。
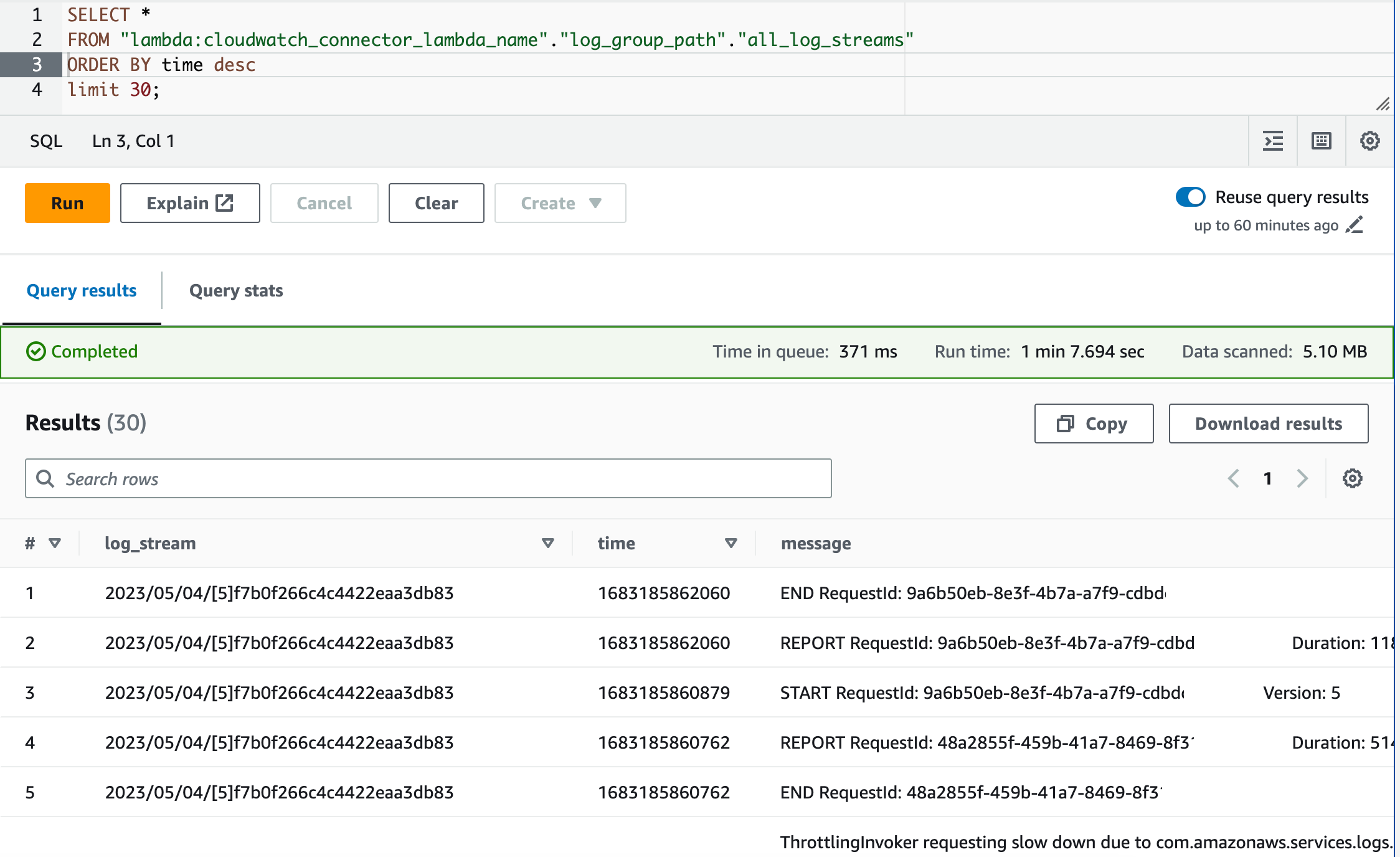
試しに、Connector Lambdaのログを検索してみたところ、なんかよく見るとスロットリングが発生しているようにも
見えます。こちらは、実運用に際してはチューニングが必要ですね。
そうそう、検証の1つでもあったAthenaV3エンジンでも動作しましたね。素晴らしい。
参照
- AWS: Amazon Athena CloudWatch connector
- Amazon Athena Query Federation
- Amazon Athena Query Federation v2023.18.1 リリース